شبکههای عصبی فیزیکاگاه#
شبکههای عصبی فیزیکآگاه، نوعی از مدلهای یادگیری ماشین هستند که بر پایه شبکههای عصبی مصنوعی، معادلات فیزیکی را مانند معادلات دیفرانسیل به صورت مستقیم در روند آموزش خود دخیل میکنند. این روش بیشتر برای حل مسائل پیچیده فیزیکی به کار میرود، بهویژه زمانی که دادههای کمی وجود دارد یا مدلسازی دقیق دشوار است. این شبکهها میتوانند جایگزینی برای روشهای عددی سنتی مانند روش المان محدود یا مونت کارلو باشند یا در کنار آنها استفاده شوند.
ویزگی شبکههای عصبی فیزیکآگاه#
گنجاندن قوانین فیزیکی:
با گنجاندن قوانین شناختهشده طبیعت در مدل، میتوان اطمینان حاصل کرد که خروجی مدل از نظر فیزیکی معتبر است و از سوی دیگر میتواند دقت کلی پیشبینیهای شبکه عصبی را افزایش دهد.
مدلهای انعطافپذیر:
این شبکهها قابلیت تقریب هر تابعی را دارند، حتی با دادههای محدود ایجاد شده یا بهدست آمده از آزمایش پیشبینیهای بسیار دقیقی انجام دهند. از سوی دیگر، میتوان مدلهای آموزش دیده را در با دادههای جدید آموزش داد و در انرژی صرفه جویی کرد.
حل مسائل پیشرو و پسرو:
توانایی حل همزمان مسائل پیشرو (مانند پیشبینی پاسخ معادلات دیفرانسیل) و پسرو (مانند پیشبینی پارمترهای داخل فرمولها) را دارند.
مقدمه#
معادلات دیفرانسیل#
معادله دیفرانسیل رابطهای ریاضی است که تغییرات یک کمیت را نسبت به کمیتی دیگر، مانند زمان یا مکان، نشان میدهد. این معادلات معمولاً برای توصیف پدیدههای طبیعی مانند حرکت، گرما یا موج به کار میروند.
به عنوان مثال میتوان به معادلات دیفرانسیل در زیر اشاره کرد
u: متغییر وابسته (پاسخ معادله دیفرانسیل)
\(x, t, r, \theta\): متغییر مستقل
معادله گرما (Heat Equation):
معادله دیفرانسیل مرتبه چهار:
معادله لاپلاس در مختصات قطبی (دیسک):
شرایط اولیه و شرایط مرزی#
معادلات دیفرانسیل میتوانند جوابهای گوناگونی داشته باشند که توانایی یافتن پاسخهای عمومی آنها به صورت عددی غیر قابل دستیابی است. بنابراین، در شبکههای عصبی فیزیکاگاه سعی در یافتن پاسخهای از معادلات دیفرانسیل در شرایط مرزی یا شرایط اولیه مشخص داریم.
الف ) شرایط اولیه#
به عنوان مثال میتوان به در دست داشتن موقعیت و سرعت اولیه یک نوسانگر هماهنگ ساده در لحظه اولیه اشاره کرد. $\( \frac{d^2 u(t)}{dt^2} + \omega^2 u(t) = 0, \quad \begin{cases} u(t=0) = 0 \\ u'(t=0) = 1 \end{cases} \)$
الف) شرایط مرزی#
بهعنوان مثال میتوان به در دست داشتن دما در ابتدا و انتهای یک میلهٔ آهنی در معادلهٔ گرما اشاره کرد: $\( \frac{\partial u(x,t)}{\partial t} = \alpha \frac{\partial^2 u(x,t)}{\partial x^2}, \quad \begin{cases} u(x=0,t) = 0 \\ u(x=1,t) = 1 \end{cases} \)$
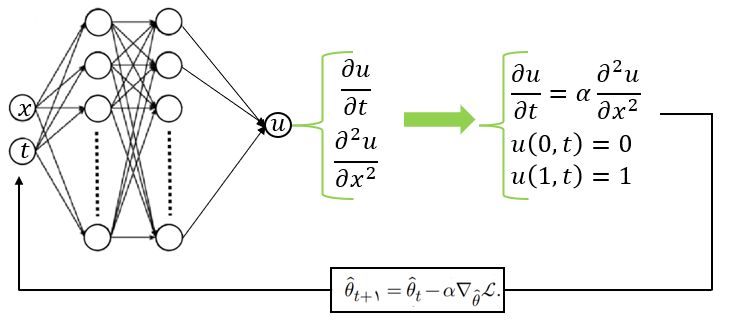
ساختار شبکههای عصبی فیزیکاگاه#
1) ورودی شبکه عصبی (متغییرهای مستقل \(x, y, z, t, r, \theta, ...\))#
2) لایههای پنهان با تعداد نورونهای مشخص#
3) خروجی شبکه عصبی (پاسخ معادله دیفرانسیل)#
4) پاسخ شبکه عصبی باید در معادله دیفرانسیل مورد نظر و شرایط مرزی و یا شرایط اولیهی آن صدق کند (تابع هزینه)#
معادله دیفرانسیل و شرایط مرزی و یا شرایط اولیه به عنوان تابع هزینه مدل شبکه عصبی هستند
6) خروجی شبکه عصبی با بهروزرسانی پارامترهای شبکه به پاسخ معادله دیفرانسیل نزدیک میشود#
بهروزرسانی پارامترهای شبکه عصبی با استفاده از الگوریتمهای بهینهسازی انجام میشود
7) هر زمان که شبکه عصبی به اندازه کافی آموزش ببیند میتوان تنها با دادن ورودیها (متغییرهای مستقل) پاسخ معادله دیفرانسیل را به پیشبینی کرد#
8) قابلیت تعمیم به معادلات دیفرانسیل مختلف#
بهجای معادله دیفرانسیل ارائهشده، بسته به نوع مسئله، میتوان از هر معادله دیفرانسیل دیگری نیز استفاده نمود. $\( \frac{d^n u}{d x^n} = F(x, u, \frac{du}{dx}, \frac{d^2 u}{dx^2}, ..., \frac{d^{n-1} x}{dx^{n-1}}) \)$
نحوه پیاده سازی روش#
:مسئله زیر را در نظر بگیرید#
معادله دیفرانسیل در شرایط اولیه و بازه مشخص به صورت زیر بیان میشود: $\( u''(t) - 10u'(t) + 9u(t) = 5t \quad \begin{cases} u(t=0) = -1 \\ u'(t=0) = 2 \end{cases} \quad t \in [0, 0.25] \)$
پاسخ معادله دیفرانسیل به صورت زیر بیان میشود: $\( u(t) = \frac{50}{81} + \frac{5}{9}t + \frac{31}{81}e^{9t} - 2e^{t} \)$
فراخوانی کتابخانهها#
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from tqdm import trange
ایجاد دادههای آموزشی#
تابع torch.linspace() در کتابخانهٔ PyTorch:#
این تابع برای ایجاد یک آرایهٔ یکبعدی از اعداد استفاده میشود. مولفهٔ اول مقدار شروع بازه، مولفهٔ دوم مقدار پایان بازه، و مولفهٔ سوم تعداد نقاط در این بازه را مشخص میکند.
import torch
# ایجاد 100 نقطه در بازهی 0 تا 1
x = torch.linspace(0, 1, 100)
print(x)
تابع view():#
این تابع برای تغییر شکل تانسور بدون کپی کردن دادههای آن به کار میرود. مولفهٔ اول تعداد سطرها و مولفهٔ دوم تعداد ستونها را مشخص میکند.
domain = (0, 0.25)
n_train = 10
t = torch.linspace(domain[0], domain[1], n_train)
print(t)
t = t.view(t.shape[0], 1) # t = t.view(-1, 1)
print(t)
tensor([0.0000, 0.0278, 0.0556, 0.0833, 0.1111, 0.1389, 0.1667, 0.1944, 0.2222,
0.2500])
tensor([[0.0000],
[0.0278],
[0.0556],
[0.0833],
[0.1111],
[0.1389],
[0.1667],
[0.1944],
[0.2222],
[0.2500]])
تاثیر تعداد دادههای آموزشی#
با افزایش تعداد دادههای آموزشی، تعداد خروجیهای شبکه عصبی نیز افزایش مییابد و در نتیجه، تابع هزینهای با اطلاعات دقیقتر، بیشتر و غنیتر حاصل میشود. در این حالت، گرادیان تابع هزینه نسبت به پارامترهای شبکه، تخمین دقیقتری از جهت نزول تابع هزینه به سمت کمینهٔ سراسری یا موضعی ارائه میدهد. این امر موجب بهروزرسانیهایی پایدارتر و مؤثرتر در فضای پارامترها شده و فرآیند همگرایی به سمت پاسخ صحیح را تسریع میکند.
-\(L(\theta)\) تابع هزینهٔ کلی است
-\(\ell(f(x_i; \theta), y_i)\) خطای مربوط به دادهٔ \(i\)ام است
-\(\theta\) پارامترهای شبکهٔ عصبی هستند
-\(N\) تعداد دادهها است.
ایجاد شبکه عصبی مصنوعی#
۱. ارثبری از کلاس nn.Module#
کلاس nn.Module، کلاس والد تمام مدلهای شبکه عصبی در کتابخانه تورچ است که باید حتماً در کلاس شبکه عصبی فراخوانی شود. این کلاس امکاناتی مانند فراخوانی پارامترها، استفاده از کارت گرافیکی، و سایر ویژگیهای ضروری برای شبکه عصبی را فراهم میکند.
۲. تابع __init__#
این تابع برای مقداردهی اولیهٔ ویژگیهای کلاس استفاده میشود و بهطور خودکار هنگام فراخوانی کلاس اجرا میشود.
۳. تابع super()#
زمانی که یک کلاس شبکه عصبی از nn.Module ارثبری میکند، تنها ارتباط بین کلاسها برقرار میشود. بنابراین، با فراخوانی این تابع ویژگیها و رفتارهای کلاس والد فراخوانی میشوند.
۴. کلاس nn.Linear#
با استفاده از این کلاس، یک لایه کاملاً متصل ایجاد میشود. مولفه اول اندازه ورودی لایه و مولفه دوم اندازه خروجی لایه را مشخص میکند. این لایه یک ماتریس با ابعاد (تعداد ورودیها، تعداد خروجیها) ایجاد میکند.
۵. تابع forward#
با فراخوانی این تابع، دادههای ورودی وارد لایههای شبکه عصبی شده و پردازش میشوند. در نهایت، خروجی نهایی شبکه عصبی محاسبه و باز میگردد.
'''
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.Tanh(),
nn.Linear(hidden_size, hidden_size),
nn.Tanh(),
nn.Linear(hidden_size, output_size)
)
def forward(self, x):
return self.net(x)
'''
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.l1 = nn.Linear(input_size, hidden_size)
self.l2 = nn.Linear(hidden_size, hidden_size)
self.l3 = nn.Linear(hidden_size, output_size)
self.tanh = nn.Tanh()
def forward(self, x):
out = self.tanh(self.l1(x))
out = self.tanh(self.l2(out))
out = self.l3(out)
return out
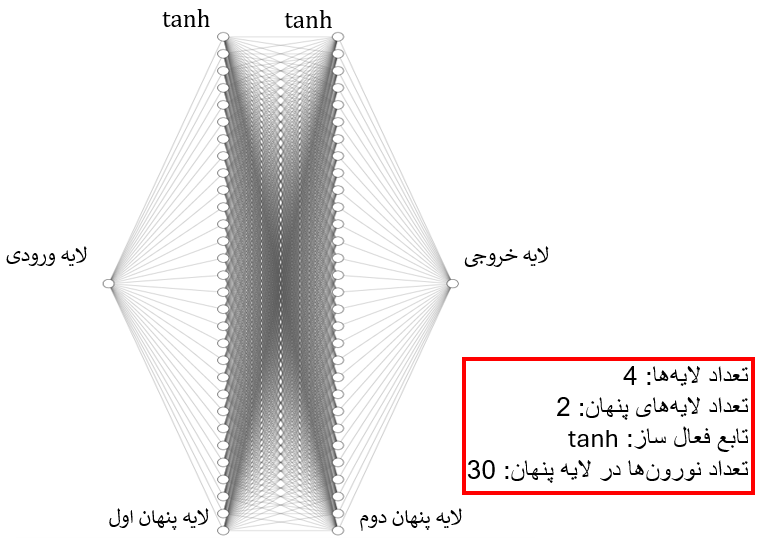
input_size, hidden_size, output_size = 1, 30, 1
model = NeuralNet(input_size, hidden_size, output_size)
model
NeuralNet(
(l1): Linear(in_features=1, out_features=30, bias=True)
(l2): Linear(in_features=30, out_features=30, bias=True)
(l3): Linear(in_features=30, out_features=1, bias=True)
(tanh): Tanh()
)
الگوریتم بهینه سازی#
کلاس torch.optim.Adam:#
در آموزش شبکه عصبی از الگوریتمی به نام الگوریتم بهینهسازی آدام استفاده میشود که زیر مجموعه الگوریتم بهینهسازی گرادیان کاهشی است.
این الگوریتم پارامترهای قابل تنظیم متفاوتی دارد که در این درس تنها به پارامتر آهنگ یادگیری بسنده میکنیم.
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# for params in model.parameters():
# print(params)
مشتقگیری از خروجیهای شبکه عصبی#
تابع torch.autograd.grad:#
این یک تابع است که امکان محاسبه گرادیان را فراهم میسازد.
create_graph=True: برای محاسبهٔ مشتق دوم و بالاتر استفاده میشود، زیرا مشتقات قبلی را ذخیره میکند تا بتوان از آنها در مشتقات بعدی استفاده کرد.grad_outputs=torch.ones_like(outputs): کتابخانه تورچ برای به دلیل کارامدی بالاتر در محاسبات تانسوری ماتریس ژاکوبی را محاسبه میکند، بنابراین برای محاسبه مشتق خروجی نسبت به ورودی باید ماتریس ژاکوبی را در یک ماتریس به فرم ماتریس خروجی ضرب کند.
بنابراین ماتریس ژاکوبی به صورت زیر خواهد بود:
from torch.autograd.functional import jacobian
def exp_reducer(x):
return x.exp()
inputs = torch.tensor([[2.0], [1.0]])
print(inputs.shape)
jacobian(exp_reducer, inputs)
torch.Size([2, 1])
tensor([[[[7.3891],
[0.0000]]],
[[[0.0000],
[2.7183]]]])
def grad(outputs, inputs):
return torch.autograd.grad(outputs, inputs, grad_outputs=torch.ones_like(outputs), create_graph=True)[0]
t.requires_grad = True
print(f"inputs: {t}\n")
u = model(t)
print(f"outputs: {t}\n")
dudt = grad(u, t)
print(f"the derivative of u with respect to t:{dudt}")
d2udt2 = grad(dudt,t)
print(f"the second derivative of u with respect to t:{d2udt2}")
inputs: tensor([[0.0000],
[0.0278],
[0.0556],
[0.0833],
[0.1111],
[0.1389],
[0.1667],
[0.1944],
[0.2222],
[0.2500]], requires_grad=True)
outputs: tensor([[0.0000],
[0.0278],
[0.0556],
[0.0833],
[0.1111],
[0.1389],
[0.1667],
[0.1944],
[0.2222],
[0.2500]], requires_grad=True)
the derivative of u with respect to t:tensor([[-0.0332],
[-0.0351],
[-0.0369],
[-0.0386],
[-0.0402],
[-0.0417],
[-0.0430],
[-0.0441],
[-0.0452],
[-0.0460]], grad_fn=<MmBackward0>)
the second derivative of u with respect to t:tensor([[-0.0718],
[-0.0679],
[-0.0637],
[-0.0592],
[-0.0546],
[-0.0497],
[-0.0447],
[-0.0396],
[-0.0343],
[-0.0291]], grad_fn=<MmBackward0>)
تابع هزینه در شبکههای عصبی آگاه از فیزیک (PINN)#
در مسئله مورد بررسی، هدف شبکه عصبی این است که خروجی شبکه بهگونهای باشد که معادله دیفرانسیل، همراه با شرایط اولیه تا حد امکان ارضا شود. این هدف با تعریف یک تابع هزینه مناسب پیادهسازی میشود که شامل مجموع خطاهای معادله و شرایط اولیه است.
در اینجا، مشتقهای اول و دوم تابع \(u(t)\) توسط شبکه عصبی تخمین زده میشوند (با استفاده از مشتقگیری خودکار). هدف این است که مقدار سمت چپ معادله در تمام نقاط دامنه به صفر نزدیک باشد.
شرایط اولیه:
تابع هزینه نهایی:
ترکیب خطای معادله دیفرانسیل و شرایط اولیه، تابع هزینه کلی زیر را تشکیل میدهد:
Note
دلیل استفاده از توان دو در جملات تابع هزینه
استفاده از توان دوم برای تمام عبارات تابع هزینه به این دلیل است که در فرایند آموزش، الگوریتم گرادیان کاهشی میکوشد مقدار تابع هزینه را کاهش دهد. اگر تابع هزینه بدون توان دوم تعریف شود، در طول آموزش مقادیر منفی تولید میشود که تا تابع هزینه را منفی کند و جهت گرادیان را در جهتی نادرست منحرف کند. بنابراین، با به توان رساندن، تابع هزینه همواره غیرمنفی باقی میماند و تضمین میشود که گرادیانها در مسیر درستی هدایت شوند.
def loss_fn(u, d2udt2, dudt, t):
L_phy = torch.mean((d2udt2 - 10*dudt + 9*u - 5*t)**2)
L_IC1 = torch.mean((u[0] + 1)**2)
L_IC2 = torch.mean((dudt[0] - 2)**2)
loss = L_phy + L_IC1 + L_IC2
return loss
تابع هزینه وزندار#
کاربرد وزنها برای کنترل سهم معادله و شرایط اولیه/مرزی در یادگیری#
در برخی مسائل، شبکه عصبی ممکن است نتواند تمامی بخشهای دامنه حل معادله دیفرانسیل را بهخوبی یاد بگیرد؛ به عنوان مثال، ممکن است شرایط مرزی یا اولیه را با دقت بالا برآورده کند، اما در نواحی داخلی دامنه عملکرد ضعیفتری داشته باشد. این عدم تعادل در یادگیری معمولاً به دلیل تفاوت مقیاس یا اهمیت اجزای مختلف تابع هزینه است. برای رفع این مشکل، میتوان از وزندهی در تابع هزینه استفاده کرد تا تأثیر هر بخش (مانند معادله دیفرانسیل، شرایط مرزی و …) را به صورت مناسب تنظیم کرد.
نقش وزنهای مختلف (بزرگتر و کوچکتر از ۱) در تنظیم تابع هزینه#
وزنهای بزرگتر از ۱: برای افزایش اهمیت یک بخش خاص از تابع هزینه (مثلاً معادله دیفرانسیل) نسبت به سایر بخشها استفاده میشوند. همچنین، اگر مقدار تابع هدف یا مشتقهای آن بسیار کوچک باشد، استفاده از وزنهای بزرگتر باعث میشود مقیاس تابع هزینه افزایش یافته و گرادیانهای بزرگتری برای بهینهسازی تولید شود!
وزنهای کوچکتر از ۱: برای کاهش سهم یک بخش خاص از تابع هزینه بهکار میروند، که منجر به کوچکتر شدن مقدار کل تابع هزینه میشود. با این حال، اگر مقدار تابع یا مشتقها ذاتاً کوچک باشد، وزنهای کوچک میتوانند فرآیند یادگیری را دشوارتر کنند و مانع از یافتن کمینه سراسری شوند. زمانی وزنهای کوچکتر از ۱ انتخاب میکنیم که بخواهیم بین جملات تابع هزنیه تعادل برقرار کنیم (پایداری آموزش شبکه عصبی را کنترل کنیم).
تنظیم وزنهای تابع هزینه: به طور کلی تنظیم سهم اهمیت هر بخش از تابع هزینه به پاسخ شبکه عصبی در پیشبینی پاسخ معادله دیفرانسیل و شرایط مرزی ویا شرایط اولیه بستگی دارد. بنابراین برای انتخاب وزنها باید بررسی کرد که شبکه عصبی در پیشبینی کدام بخش از تابع هزینه بهتر یا بدتر عمل کرده در نهایت اهمیت بخش یا بخشهایی را که در پیشبینی آنها بدتر عمل کرده را بیشتر کرد.
def loss_fn(u, d2udt2, dudt, t, weights):
w1, w2, w3 = weights
L_phy = w1*torch.mean((d2udt2 - 10*dudt + 9*u - 5*t)**2)
L_IC1 = w2*torch.mean((u[0] + 1)**2)
L_IC2 = w3*torch.mean((dudt[0] - 2)**2)
L_total = L_phy + L_IC1 + L_IC2
return L_total, L_phy, L_IC1, L_IC2
آموزش شبکه عصبی#
num_itrs = 2000
itr_show = 100
weight = (1, 100, 100)
L_total_history = []
L_phy_history = []
L_IC1_history = []
L_IC2_history = []
pbar = trange(num_itrs)
for itr in pbar:
u = model(t)
dudt = grad(u, t)
d2udt2 = grad(dudt, t)
loss, L_phy, L_IC1, L_IC2 = loss_fn(u, d2udt2, dudt, t, weight)
loss.backward()
optimizer.step()
optimizer.zero_grad()
L_total_history.append(loss.item())
L_phy_history.append(L_phy.item())
L_IC1_history.append(L_IC1.item())
L_IC2_history.append(L_IC2.item())
pbar.set_postfix({'loss': loss.item()})
# if itr % itr_show == 0:
# print(f'iteration {itr}/{num_itrs}, loss = {loss.item():.6f}')
100%|████████████████████████████████████████████████████████████████| 2000/2000 [00:08<00:00, 245.59it/s, loss=0.0305]
بهرهبرداری از شبکه عصبی مصنوعی#
n_test = 1000
def exact_solution(t):
return 50/81 + (5/9) * t + (31/81)*torch.exp(9*t) - 2*torch.exp(t)
t_test = torch.linspace(domain[0], domain[1], n_test)
t_test = t_test.view(t_test.shape[0], 1)
predicted = model(t_test)
analytic_cal = exact_solution(t_test)
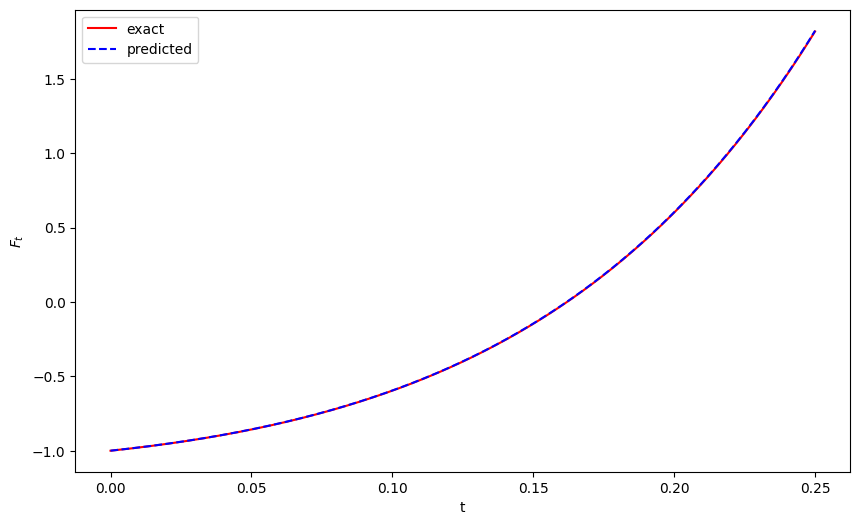
plt.figure(figsize=(10, 6))
plt.plot(t_test.detach().numpy(), analytic_cal.detach().numpy(), "r", label="exact")
plt.plot(t_test.detach().numpy(), predicted.detach().numpy(), "b--", label="predicted")
plt.xlabel("t")
plt.ylabel("$F_t$")
plt.legend()
plt.show()
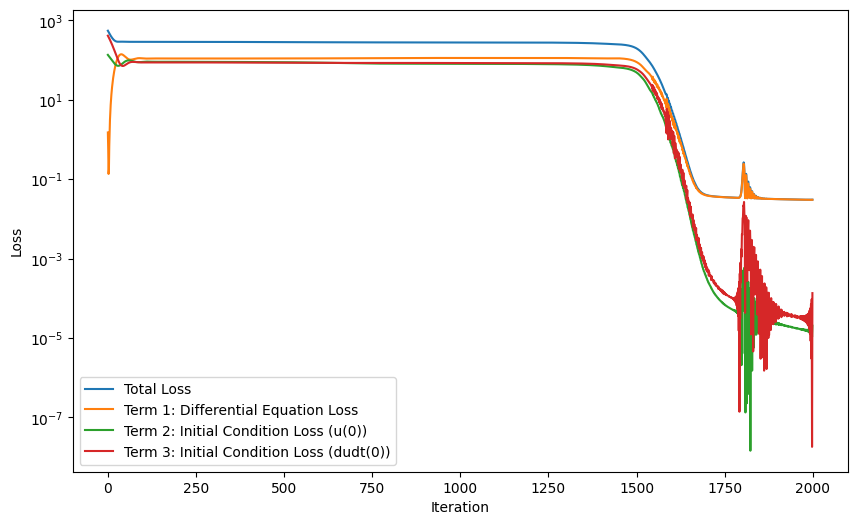
plt.figure(figsize=(10, 6))
plt.semilogy(L_total_history, label="Total Loss")
plt.semilogy(L_phy_history, label="Term 1: Differential Equation Loss")
plt.semilogy(L_IC1_history, label="Term 2: Initial Condition Loss (u(0))")
plt.semilogy(L_IC2_history, label="Term 3: Initial Condition Loss (dudt(0))")
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.legend()
plt.show()
mse = torch.mean((predicted - analytic_cal)**2)
print(f'Mean Squared Error: {mse.item()}')
Mean Squared Error: 3.4085621791746235e-06
پیادهسازی نهایی#
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from tqdm import trange
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.l1 = nn.Linear(input_size, hidden_size)
self.l2 = nn.Linear(hidden_size, hidden_size)
self.l3 = nn.Linear(hidden_size, output_size)
self.tanh = nn.Tanh()
def forward(self, x):
out = self.tanh(self.l1(x))
out = self.tanh(self.l2(out))
out = self.l3(out)
return out
class Trainer:
def __init__(self, model, optimizer, domain, weights):
self.model = model
self.optimizer = optimizer
self.domain = domain
self.weights = weights
self.L_total_history = []
self.L_phy_history = []
self.L_IC1_history = []
self.L_IC2_history = []
def exact_solution(self, t):
return 50/81 + (5/9) * t + (31/81)*torch.exp(9*t) - 2*torch.exp(t)
def grad(self, outputs, inputs):
return torch.autograd.grad(outputs, inputs, grad_outputs=torch.ones_like(outputs), create_graph=True)[0]
def generate_data(self, n_data):
data = torch.linspace(self.domain[0], self.domain[1], n_data)
data = data.view(data.shape[0], 1)
return data
def loss_fn(self, u, d2udt2, dudt, t):
w1, w2, w3 = self.weights
L_phy = w1 * torch.mean((d2udt2 - 10*dudt + 9*u - 5*t)**2)
L_IC1 = w2 * torch.mean((u[0] + 1)**2)
L_IC2 = w3 * torch.mean((dudt[0] - 2)**2)
L_total = L_phy + L_IC1 + L_IC2
return L_total, L_phy, L_IC1, L_IC2
def train(self, n_train, num_itr, show_itr=False):
t = self.generate_data(n_train)
t.requires_grad = True
pbar = trange(num_itr)
for itr in pbar:
u = self.model(t)
dudt = self.grad(u, t)
d2udt2 = self.grad(dudt, t)
loss, L_phy, L_IC1, L_IC2 = self.loss_fn(u, d2udt2, dudt, t)
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
self.L_total_history.append(loss.item())
self.L_phy_history.append(L_phy.item())
self.L_IC1_history.append(L_IC1.item())
self.L_IC2_history.append(L_IC2.item())
if show_itr and itr % 100 == 0:
print(f'iteration {itr}/{num_itr}, loss = {loss.item():.6f}')
else:
pbar.set_postfix({'loss': loss.item()})
def evaluation(self, n_test):
t_test = self.generate_data(n_test)
predicted = self.model(t_test)
analytic_cal = self.exact_solution(t_test)
plt.figure(figsize=(10, 6))
plt.plot(t_test.detach().numpy(), analytic_cal.detach().numpy(), "r", label="exact")
plt.plot(t_test.detach().numpy(), predicted.detach().numpy(), "b--", label="predicted")
plt.xlabel("t")
plt.ylabel("$F_t$")
plt.legend()
plt.show()
plt.figure(figsize=(10, 6))
plt.semilogy(self.L_total_history, label="Total Loss")
plt.semilogy(self.L_phy_history, label="Term 1: Differential Equation Loss")
plt.semilogy(self.L_IC1_history, label="Term 2: Initial Condition Loss (u(0))")
plt.semilogy(self.L_IC2_history, label="Term 3: Initial Condition Loss (dudt(0))")
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.legend()
plt.show()
mse = torch.mean((predicted - analytic_cal)**2)
print(f'Mean Squared Error: {mse.item()}')
torch.manual_seed(42)
n_train, n_test, num_itr, itr_show = 100, 100, 2000, 100
weights, domain = (0.01, 1, 1), (0, 0.25)
learning_rate = 0.001
input_size, hidden_size, output_size = 1, 30, 1
model = NeuralNet(input_size, hidden_size, output_size)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
trainer = Trainer(model, optimizer, domain, weights)
trainer.train(n_train, num_itr, show_itr=False)
trainer.evaluation(n_test)
41%|████ | 811/2000 [00:10<00:15, 78.96it/s, loss=2.66]
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[2], line 12
8 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
10 trainer = Trainer(model, optimizer, domain, weights)
---> 12 trainer.train(n_train, num_itr, show_itr=False)
14 trainer.evaluation(n_test)
Cell In[1], line 74, in Trainer.train(self, n_train, num_itr, show_itr)
72 print(f'iteration {itr}/{num_itr}, loss = {loss.item():.6f}')
73 else:
---> 74 pbar.set_postfix({'loss': loss.item()})
File ~/.virtualenvs/physcomp/lib/python3.8/site-packages/tqdm/std.py:1431, in tqdm.set_postfix(self, ordered_dict, refresh, **kwargs)
1428 self.postfix = ', '.join(key + '=' + postfix[key].strip()
1429 for key in postfix.keys())
1430 if refresh:
-> 1431 self.refresh()
File ~/.virtualenvs/physcomp/lib/python3.8/site-packages/tqdm/std.py:1347, in tqdm.refresh(self, nolock, lock_args)
1345 else:
1346 self._lock.acquire()
-> 1347 self.display()
1348 if not nolock:
1349 self._lock.release()
File ~/.virtualenvs/physcomp/lib/python3.8/site-packages/tqdm/std.py:1495, in tqdm.display(self, msg, pos)
1493 if pos:
1494 self.moveto(pos)
-> 1495 self.sp(self.__str__() if msg is None else msg)
1496 if pos:
1497 self.moveto(-pos)
File ~/.virtualenvs/physcomp/lib/python3.8/site-packages/tqdm/std.py:459, in tqdm.status_printer.<locals>.print_status(s)
457 def print_status(s):
458 len_s = disp_len(s)
--> 459 fp_write('\r' + s + (' ' * max(last_len[0] - len_s, 0)))
460 last_len[0] = len_s
File ~/.virtualenvs/physcomp/lib/python3.8/site-packages/tqdm/std.py:452, in tqdm.status_printer.<locals>.fp_write(s)
451 def fp_write(s):
--> 452 fp.write(str(s))
453 fp_flush()
File ~/.virtualenvs/physcomp/lib/python3.8/site-packages/tqdm/utils.py:196, in DisableOnWriteError.disable_on_exception.<locals>.inner(*args, **kwargs)
194 def inner(*args, **kwargs):
195 try:
--> 196 return func(*args, **kwargs)
197 except OSError as e:
198 if e.errno != 5:
File ~/.virtualenvs/physcomp/lib/python3.8/site-packages/ipykernel/iostream.py:670, in OutStream.write(self, string)
667 msg = f"write() argument must be str, not {type(string)}" # type:ignore[unreachable]
668 raise TypeError(msg)
--> 670 if self.echo is not None:
671 try:
672 self.echo.write(string)
KeyboardInterrupt: