یادگیری ماشین و شبکههای عصبی#
یادگیری ماشین در سالهای اخیر به یکی از ابزارهای کلیدی در تحلیل دادههای فیزیکی تبدیل شده است. در این بخش، مفاهیم پایهای ولی ضروری را بررسی میکنیم که مبنای درک و استفاده از مدلهای یادگیری ماشین، مخصوصاً شبکههای عصبی مصنوعی (Artificial Neural Networks)، را تشکیل میدهند.
۱. دادهها و نمایش ماتریسی#
در یادگیری ماشین، دادهها نقش اصلی را ایفا میکنند. صرفنظر از نوع داده (تصویر، طیف انرژی، سیگنال، متن و …)، در نهایت تمام آنها را میتوان به صورت عددی نمایش داد.
مثالهایی از نمایش عددی دادهها:
یک تصویر ۲۸ در ۲۸ پیکسلی → ماتریس ۲۸×۲۸ از اعداد (مقادیر شدت پیکسلها)
طیف انرژی حاصل از یک آشکارساز → یک بردار از مقادیر شدت یا شمارش
اطلاعات یک رویداد در آشکارساز → چندین بردار از ویژگیهایی مانند مکان، انرژی، زمان و …
✅ نتیجه: اولین گام در یادگیری ماشین، نمایش دادهها به شکل بردار یا ماتریس عددی است.
دیتاست MNIST#
یکی از دیتاست های مشهور برای تمرین کردن با داده و شبکه های عصبی است. این دیتاست شامل دست خط تعدادی دانشجو است که ارقام انگلیسی را نوشته اند. نام MNIST از این واقعیت میآید که این مجموعه، نسخهی اصلاحشدهای از دو مجموعه دادهی جمعآوریشده توسط NIST (مؤسسه ملی استانداردها و فناوری ایالات متحده) است.
در ادامه، چند نمونه تصویر از MNIST را میتوان مشاهده کرد:

ساختار مجموعه دادهی MNIST#
مجموعه دادهی MNIST از دو بخش تشکیل شده است:
1. دادههای آموزشی (Training Data)#
شامل ۶۰٬۰۰۰ تصویر سیاه و سفید (greyscale)
ابعاد هر تصویر: ۲۸ در ۲۸ پیکسل
جمعآوریشده از ۲۵۰ نفر:
نیمی از آنها کارمندان ادارهی آمار ایالات متحده (US Census Bureau)
نیمی دیگر دانشآموزان دبیرستانی
این ۶۰ هزار داده، خود به دو دسته ی ۵۰ هزارتایی و ۱۰ هزارتایی تقسیم شده اند. بعدا دلیل این کار را بیشتر خواهیم فهمید
2. دادههای آزمایشی (Test Data)#
شامل ۱۰٬۰۰۰ تصویر سیاه و سفید
ابعاد: ۲۸ در ۲۸ پیکسل
جمعآوریشده از ۲۵۰ فرد متفاوت نسبت به دادههای آموزشی
باز هم نیمی کارمند اداره آمار و نیمی دانشآموز
Note
هدف از دادههای آزمایشی
از دادههای آزمایشی برای ارزیابی میزان یادگیری استفاده میکنیم.
از آنجا که این دادهها از افرادی متفاوت با دادههای آموزشی گرفته شدهاند، این کار به ما اطمینان میدهد که:
توانایی تشخیص ارقام از دستخطهایی که پیشتر دیده نشده است نیز.
#A simple code to load and show MNIST dataset
#### Libraries
# Standard library
import pickle
import gzip
# Third-party libraries
import numpy as np
import matplotlib.pyplot as plt
def download_dataset(url, filename):
"""
Download the dataset from the given URL if it is not already present.
این متد در ابتدا چک میکند که آیا فایل در مسیر داده شده وجود دارد یا خیر.
اگر فایل وجود نداشته باشد، آن را از آدرس داده شده (url) دانلود میکند.
"""
import os
import requests
# make sure the directory exists
os.makedirs(os.path.dirname(filename), exist_ok=True)
# Check if the file already exists
# If it does not exist, download it
# If it does exist, do nothing
if not os.path.exists(filename):
print(f"Downloading {filename}...")
response = requests.get(url)
with open(filename, 'wb') as f:
f.write(response.content)
print(f"Downloaded {filename}")
return True
def load_data():
"""
Load the MNIST dataset from a gzipped pickle file.
این متد دادههای MNIST را از یک فایل gzipped pickle بارگیری میکند.
آن را به صورت سه دسته training_data, validation_data و test_data برمیگردد.
این دادهها شامل تصاویر و برچسبهای مربوط به اعداد دستنویس هستند.
"""
# Download the dataset if it is not already present
dataset_url = 'https://github.com/unexploredtest/neural-networks-and-deep-learning/raw/refs/heads/master/data/mnist.pkl.gz' #'http://deeplearning.net/data/mnist/mnist.pkl.gz'
dataset_filename = '../data/mnist.pkl.gz'
download_dataset(dataset_url, dataset_filename)
f = gzip.open('../data/mnist.pkl.gz', 'rb')
u = pickle._Unpickler(f)
u.encoding = 'latin1'
training_data, validation_data, test_data = u.load()
f.close()
return (training_data, validation_data, test_data)
def show_data(data , index=0 , ax=None):
"""
Show the MNIST data.
"""
# Extract the first image and label from the training data
image, label = data[0][index], data[1][index] #loads the image and its label
# data is stored as a flat array of 784 pixels (28x28)
# Reshape the image to 28x28 pixels
image = image.reshape(28, 28)
# Display the image
ax.imshow(image, cmap='gray')
ax.set_title(f'Label: {label}')
ax.axis('off')
fix , axs = plt.subplots(1 , 10 , figsize=(30,3))
training_data, validation_data, test_data = load_data()
for i in range(10):
# Show the first 10 images and their labels
label = show_data(training_data , i ,axs[i])
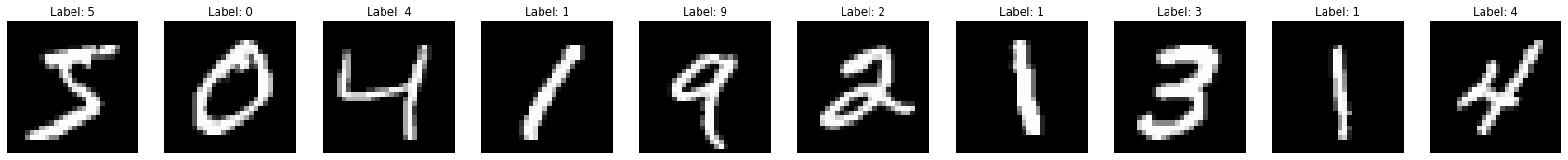
۲. یادگیری ماشین: نگاشت ورودی به خروجی#
مثالی از یادگیری انسان
ابتدا کودک عکسها یا شکلهایی از گربه را مشاهده میکند.


سپس، توان تشخیص گربه را دارد.


یادگیری به عنوان پیدا کردن یک تابع#
یادگیری ماشین را میتوان به صورت یافتن یک تابع در نظر گرفت که دادههای ورودی را به خروجیهای مورد انتظار نگاشت میدهد.
هدف، یافتن تابعی است مانند:
که برای هر ورودی x، خروجی پیشبینیشده ŷ را تولید کند، بهگونهای که به مقدار واقعی y نزدیک باشد.
مثال: BDT (Boosted Decision Trees)
این الگوریتم با استفاده از ترکیب چند درخت تصمیم، سعی میکند تابعی را پیدا کند که ویژگیهای ورودی را به خروجی نگاشت دهد.
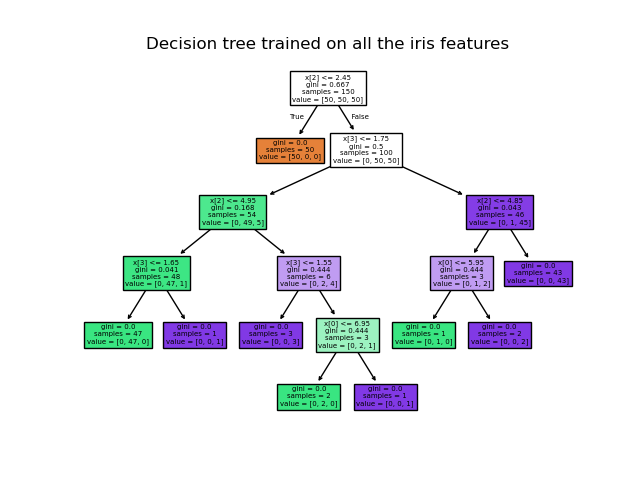
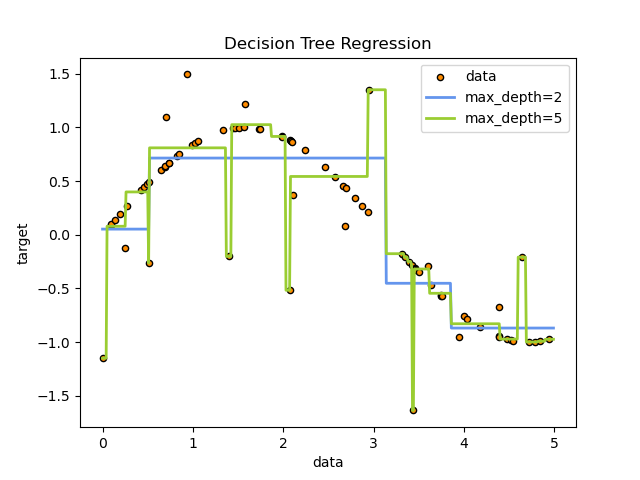
Note
توضیحات مربوط به این شکلها را میتوانید در سایت پکیج scipy ملاحظه کنید.
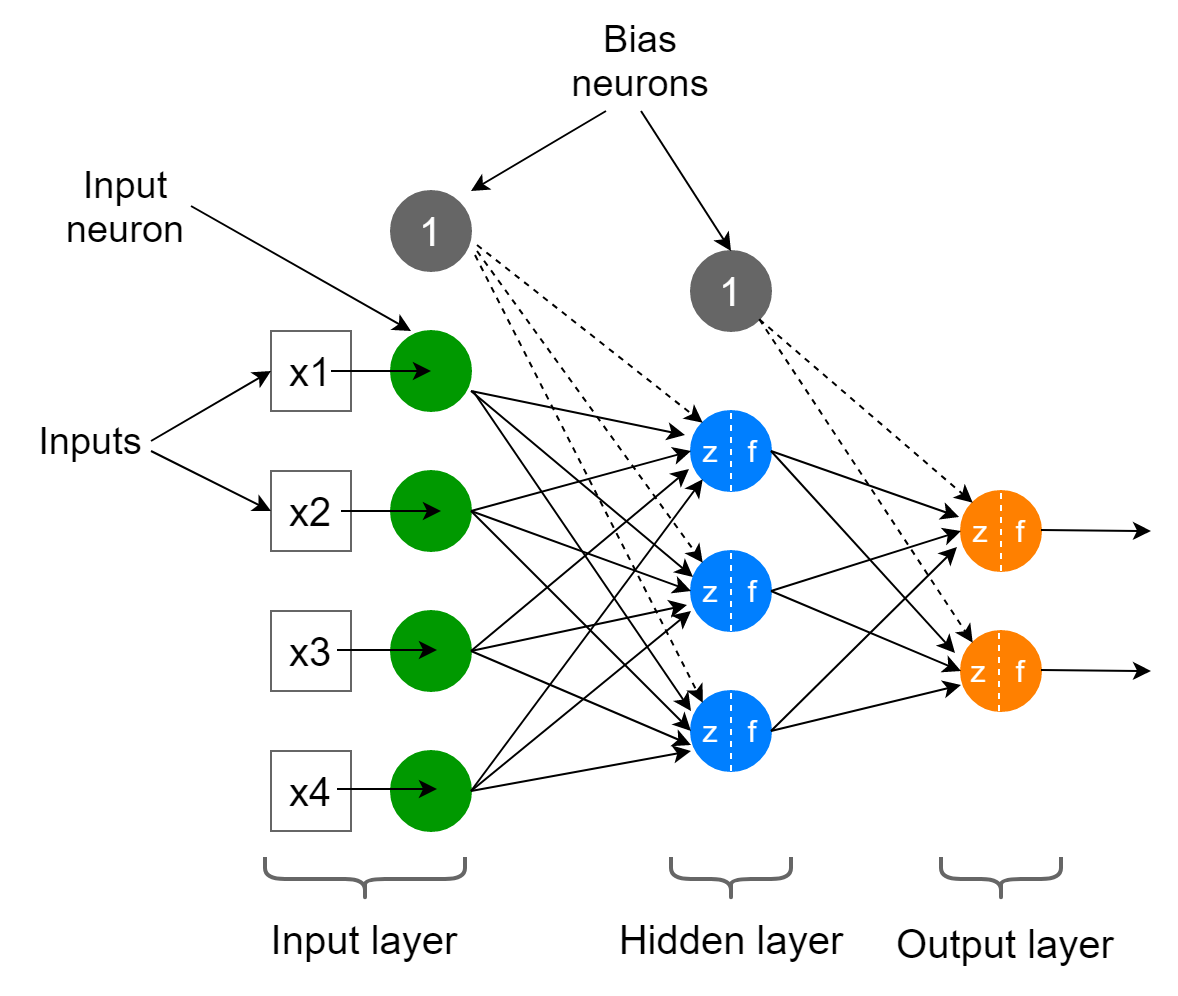
۳. شبکههای عصبی به عنوان تابع#
شبکههای عصبی را میتوان به صورت یک تابع ریاضی قابل آموزش نمایش داد که از ترکیب ضربهای ماتریسی و توابع فعالسازی غیرخطی ساخته شده است.
فرض کنیم:
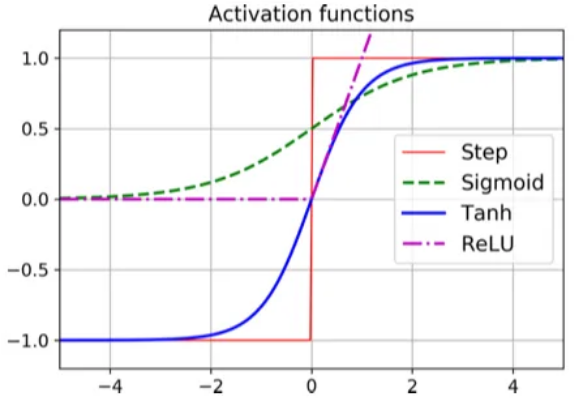
x: بردار ورودیW₁,W₂: ماتریس وزنهاb₁,b₂: بایاسهاσ: تابع فعالسازی (مثلاً ReLU یا Sigmoid)
فرمول ساده برای یک شبکه با یک لایه پنهان:
میتوان نمایی شماتیک از این تابع را به صورت زیر نشان داد:
تصویر تابع شبکهی عصبی
توابع فعالسازی
۴. تقریب هر تابع دلخواه#
بر اساس قضیهی تقریب جهانی (Universal Approximation Theorem):
یک شبکه عصبی با تنها یک لایه پنهان و تعداد کافی نرون میتواند هر تابع پیوسته را با دقت دلخواه تقریب بزند.
این یعنی:
حتی اگر تابع مورد نظر پیچیده یا ناشناخته باشد، شبکه عصبی میتواند آن را مدلسازی کند.
در عمل، محدودیتهایی مثل اندازه شبکه، تعداد داده، یا overfitting وجود دارد، اما اصل توانمندی وجود دارد.
پارامترهای تابع شبکهی عصبی#
تمام اعضاء Wها و bها پارامترهای آزاد هستند.
Note
تابع هزینه و برازش#
تابعی شبیه به \(\chi^2\) که با کمینه کردن آن بتوان پارمترهای بهینه را یافت.
البته گزینه های دیگری هم وجود دارد:
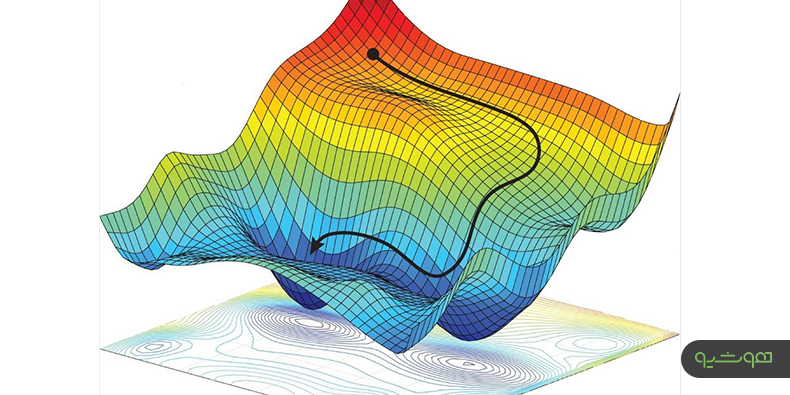
۵. مشتقگیری و بهینهسازی پارامترها#
هدف اصلی: کمینهسازی تابع هزینه (L) با تنظیم پارامترهای شبکه (θ):
گرادیان کاهشی#
الگوریتم پسانتشار (Backpropagation)#
محاسبه گرادیانها با قاعده زنجیرهای برای یک شبکه دو لایه:
محاسبه گرادیان لایه خروجی:
\[ \frac{\partial L}{\partial W_2} = \frac{\partial L}{\partial f} \cdot \sigma_2' \cdot h_1^T \]که در آن
h_1خروجی لایه پنهان است.محاسبه گرادیان لایه پنهان:
\[ \frac{\partial L}{\partial W_1} = \left(\frac{\partial L}{\partial f} \cdot W_2 \odot \sigma_1'\right) x^T \]